
What is MRF?
March 30, 2023

For some crazy reason, more than a few people had enough time to read my last post on the anniversary of MRF. Thanks to you all! I really appreciated a lot of the feedback I got from folks. I have been delayed in getting part 2 out, but hopefully better late than never. In the meantime, Efrat was kind enough to send a picture of our dinner that inspired this whole thing:

Thanks Efrat! In that last post, I described how we got from quantitative imaging with compressed sensing to MRF. As the title suggests, again based on this conversation from Sedona, I thought it would be useful to describe how we think about MRF from an acquisition and reconstruction perspective. When I first showed MRF to Paul Bottomley, he suggested we name it “MOPES— The Mother of All Pulse Sequences”. While I don’t believe he’s \necessarily wrong in that description (that’s why it was published in Nature), it may not be as useful for the field. So to make things a little easier to see, I thought it would be useful to go back through some of our early patents and papers. As part of this, I’d really like to highlight the role of our former patent attorney and dear friend of mine, JT Kalnay, who unexpectedly passed away in 2016.
Writing Patents for Clarity
When I started in MRI in the early 1990s, I thought patents held back innovation and that everything should be open. But since the late 1990s, my perspective has almost completely reversed. I have realized that in order to make anything with a sustained impact on patient care, you either had to have continuous government support (through grants, etc) or you had to get your development into the hands of a for-profit company who could make money. In order to do this, these companies have to have the freedom to operate, and this requires patent protection. I haven’t seen a sustainable “other way” yet. There’s an awesome movement in our field right now to open source as much as possible, and we may be nearing a time when there’s enough momentum from governments and private foundations for these approaches to make a real impact, but this is still at an early stage. For example, it’s still unclear to me how open-source projects will receive regulatory approval, etc. without significant investment. But 10 years ago, it was absolutely clear we needed patents in order for MRF to make a difference.
Much like writing a good grant or a good paper, writing a good patent requires a lot of work. The nice thing about going through the process of writing a patent is that it requires you to develop a very clear description of what it is that you’re patenting… in fact that’s the whole purpose of a patent! You can’t just say “I’d like to patent an MRI scanner that makes perfect images every time.” You have to precisely describe the process you will use to make that happen.
Through this whole journey of writing a patent it helps to have a great partner who can challenge your beliefs and expand your thought process. Throughout the early days of MRF, that was JT Kalnay. JT was an amazing person. Friend of Steve Jobs. Former running partner of Christy Brinkley (and reluctant fishing partner of Billy Joel.) He would send me pictures of him competing in pulling train cars (really!), climbing to Machu Picchu from the back side over 5000 m mountains or falling off big rocks in Joshua Tree. He was close friends with Serena Williams’s agent, so we would often get his tickets to the Cleveland Cavaliers so that we could watch Lebron James play from the front row sitting across the aisle from Usher. He was an amazing superhuman and I am so fortunate that I got to spend as much time with him as I did. I really miss him.

When it came to patent writing, JT had a knowledge base like no other. He was an applied mathematician by training who had worked under Dennis Ritchie (the creator of the C programming language) among many others. When his wife, Susanne Brady-Kalnay, had become faculty at Case, he looked around and realized that imaging was the place where he could have an impact and dedicated himself to learning everything he could. He took Bob Brown’s graduate level class (using Bob and Mark Haake’s Green Bible of MRI) along with every other class that he could. Through Jeff Duerk, he became our patent attorney for everything imaging related on campus.
Especially in the early days, JT provided a key voice in honing our thought process so that we could really understand what MRF was and what it could do. We had such a tight word limit in the original paper that, especially in retrospect, we couldn’t be as descriptive as we would have liked. So to get to a simple answer to the title of this post, I’d like to go through the framing that we developed with JT over several months of discussions that landed in our first patent for MRF dating back to 2011, US Patent 10,627,468, which has also been granted in multiple foreign countries as well. To my lawyer friends who might be reading, this will not be an exhaustive or limiting discussion of this patent— this is only meant as an educational tool for clarity.
The Three Main Components of MRF
After going through many iterations, the most general form of MRF that we settled on has three main components: 1) an MRF excitation that varies over the course of the scan including data acquisition blocks 2) reference information about the expected signal evolutions and 3) a process to compare the acquired data to the reference information to quantify either the presence of a material or to quantify a property of a material. Prior to MRF, NMR acquisitions may have had portions of that process, but at least in patent-land, this was the first time that these had been been put together to do something useful. Everything else in the patent expands on details of these three key components, and going through some of these might be helpful for the community. The most general form of MRF is in claim #1 and it’s a lot of patent-speak, but we will break this down as we go on.
1. A method, comprising:
exposing a material to nuclear magnetic resonance (NMR) fingerprinting excitation using an NMR system by:
controlling the NMR apparatus to apply radio frequency (RF) energy to the material *in a series of variable sequence blocks*, where a sequence block includes one or more excitation phases, one or more readout phases, and one or more waiting phases,
where the material contains a plurality of resonant species,
where the RF energy applied during a sequence block is configured to cause the plurality of resonant species in the material to simultaneously produce NMR signals, wherein each resonant species in the material simultaneously produces a respective NMR signal to produce the NMR signals, and
where at least one member of the series of variable sequence blocks differs from at least one other member of the series of variable sequence blocks in at least N sequence block parameters, N being an integer greater than one;
acquiring NMR signals from the material elicited by the NMR fingerprinting excitation; and
indicating a presence of the material and quantifying a property of the material exposed to the NMR fingerprinting excitation by *comparing* first information associated with the NMR signals acquired from the material in response to the NMR fingerprinting excitation to *reference information* associated with the NMR fingerprinting excitation.
I’ve bolded the three primary concepts in the middle of the rest of the text. Let’s take a look at these in a little more detail.
MRF Sequences
So what makes an MRF excitation? In the original Nature paper, we showed several excitation patterns with a bSSFP sequence with very different signal evolutions that still gave the same quantitative results. In that case, both the flip angle and TR were varied throughout the acquisition. In reality there are an infinite number of sequences that one could run in any given situation. But not every acquisition is MRF, so how would one describe this in a way that is both specific and general? This is where patent language can be helpful. Again with JT’s insight, we developed a formalism that helps define an MRF sequence.
We start with the most basic definition of a “sequence block” that has at least one RF pulse, at least one readout and at least one waiting time. The way I like to think about sequences like this is to start with one readout and either go forward or backward to the next readout. Everything that happens in between, whether RF pulses, gradient spoiling or refocusing, or waiting times can be considered part of that sequence block.
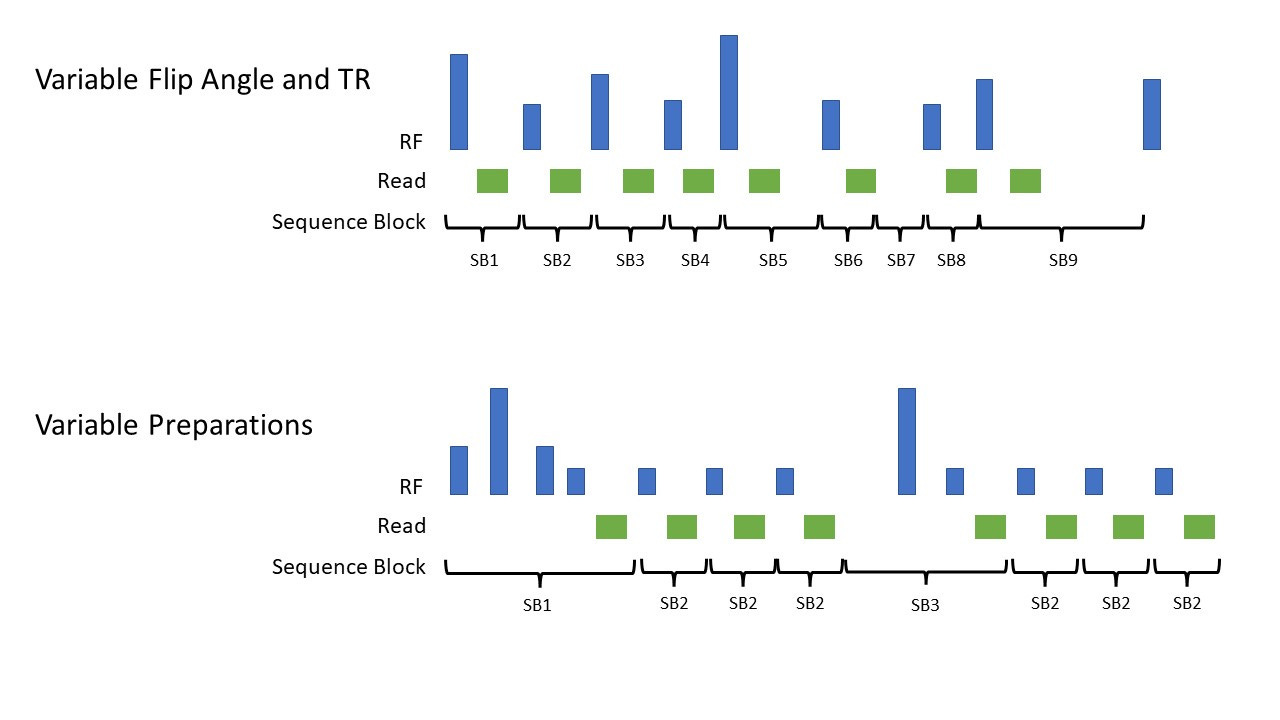
Based on this definition, an MRF acquisition can be defined as a sequence with two or more types of sequence blocks per acquisition. (Later patents cover the case of three, four and more types of sequence blocks.) As we’ve seen, it doesn’t really matter what varies within the sequence… almost anything that you change will result in a differential effect on the signal for different types of tissues/materials, which is the overall goal of MRF. Obviously some sequence choices work better than others, but the general ideal holds. Some examples of this include varying the RF flip angle or TR multiple times in the acquisition or changing the preparation pulses used in different sequence blocks. This is shown in the figure below. In the first case, we end up with many types of sequence blocks (numbered SB1-SB9 here) since the “stuff” happening between readouts is different for each TR. This is the type of sequence that we showed in the original paper. In the second MRF sequence, originally published by Jessie Hamilton et al, we vary the preparation scheme multiple times throughout the acquisition. This can work even with a constant flip angle in between the preparation modules. In the case below, we start with a T2 preparation module and then later a T1 preparation through inversion recovery. In terms of our sequence block model, everything up until the first readout is part of sequence block 1. We then have repeated copies of sequence block 2 as the magnetization is evolving. We then do sequence block 3 with the delay and inversion recovery pulse, and then back to sequence block 2.
While JT was amazing at helping us put together our thoughts, he was adamant that he couldn’t generate ideas on his own. So I still remember the day sitting in my office where he asked “OK, so what are all of the things you can change in a sequence block?” It’s not easy to concisely describe everything that we can do in NMR! The list we came up with eventually made it to claim #11 in the original patent:
11. The method of claim 1, where the sequence block parameters comprise echo time, flip angle, phase encoding, diffusion encoding, flow encoding, RF pulse amplitude, RF pulse phase, number of RF pulses, type of gradient applied between an excitation portion of a sequence block and a readout portion of a sequence block, number of gradients applied between an excitation portion of a sequence block and a readout portion of a sequence block, type of gradient applied between a readout portion of a sequence block and an excitation portion of a sequence block, number of gradients applied between a readout portion of a sequence block and an excitation portion of a sequence block, type of gradient applied during a readout portion of a sequence block, number of gradients applied during a readout portion of a sequence block, amount of RF spoiling, and amount of gradient spoiling.
You can’t just write “anything”!
But we’ve seen MRF using sequences structures based on bSSFP, SSFP, FLASH, EPI, QUEST and mixtures of all of these. I’m sure I’m missing some and I’m positive we will see more in the coming years! I’m excited to see what the community can do!
The Reference Information
The goal of an MRF sequence is actually pretty simple: we want different tissues to have different signal evolutions so that they are separable. We don’t care what those evolutions are— we just want them to be different. But in order to recognize these different evolutions in the third step, we have to know what to expect in the first place. There are obviously a lot of ways to do this, but we anticipated that the majority of MRF would be solved using direct simulations of the physics involved. In the original paper we used a pretty simplistic Bloch simulation. But since then, our group and others have included almost every physical effect you can think of including (and this is not an exhaustive list): B0 inhomogeneities, transmit inhomogeneities (here and here), slice profiles, receive inhomogeneities, motion, partial volume, flow, vascular effects (here and here), diffusion, exchange (here, here, here, and here) and I’m *positive* I’m missing something else… zero quantum?… but you can really incorporate every physical effect you can think of into this reference information. One of the key features of MRF is that this can be calculated as a purely forward problem. We don’t have to solve an inverse problem at this stage. We just need to be able to calculate the expected signal evolutions for materials with known properties. This is a feasible problem for essentially everything we do in MRI.
Even though there’s not many people exploring it, there is also the possibility to use acquired data itself as reference information. This has been useful in certain circumstances where one may not fully understand all of the properties of the scanner. As an example of this, we’ve used this to essentially do MRF in reverse on some novel systems. We take phantoms with known physical properties, like T1 and T2, and then do MRF to back out important system properties, like absolute B1 scaling or other effects. It’s an important tool to have in your back pocket every once in a while!
In terms of the patent language, the specific list of reference information is in claim #6:
6. The method of claim 1, where the reference information includes one or more of, a previously acquired NMR signal, a modeled NMR signal, a previously acquired signal evolution, a modeled signal evolution, information derived from a reference signal evolution, and non-signal evolution information.
Comparison
The last part is were we compare the acquired data to the reference information to derive the material properties that we’re interested in. Again, these material properties can be almost anything, assuming that the sequence provides different signal evolutions for different materials and that we have information as to what these different signal evolutions look like. We very specifically chose the term “compare” here because we were fully aware that there could be a lot of different options for this step, and had tried essentially everything early on to see what worked best. In the patent language, we again made a comprehensive list that made it into claims 8-10:
8. The method of claim 1, where comparing the first information to the reference information includes one or more of, pattern matching, selecting, minimizing, and optimizing.
9. The method of claim 8, where pattern matching includes one or more of, orthogonal matching pursuit, categorical sequence labeling, regression, clustering, classification, real valued sequence labeling, parsing, Bayesian methods, Markov methods, ensemble learning methods, and template matching.
10. The method of claim 8, where optimization includes one or more of, least squares optimization, regularized least squares optimization, basis pursuit optimization, and matching pursuit optimization.
As you can see this list includes pretty much everything from the template matching used in the original paper through to non-linear fitting and neural networks. Over the years we’ve gone through a lot of different methods, but more and more I personally see real power in using dictionaries of solutions as the future for MRF and beyond, even if only in an inner loop of a large optimization. Instead of posting another 1000+ word rant about dictionaries vs fitting vs whatever here, I moved that to another post which you can find here. But to summarize most of that information here, we have continued to focus on dictionary-based methods because they provide a fast, direct and robust way to get answers in MRF. Even in the world of awesome methods like unrolled iterative methods based on deep learning, dictionaries are an efficient way to get this job done. We currently use a parallelized dictionary method in our on-scanner reconstruction and it takes less than 5 seconds to calculate the dictionary, so we do that at the beginning of the acquisition. The reconstruction for a 3D whole-brain MRF scan takes less than a minute, and that’s dominated by gridding+FFT, not by the dictionary calculation.

So I hope that gives you a good overview of our initial concept of the three key components of MRF and some if our recent developments. Besides my dictionary rant, I’ll try to post some updates on our clinical use of MRF in the coming weeks. Thanks for reading this far! Let me know if you have any questions or thoughts!
Best wishes!
—Mark